
笔记:MySQL技术内幕-05
B+树:高度平衡、高扇出性
聚集索引:PRIMARY主键的索引,B+树结构,叶子节点包含行数据,适合范围查找;
辅助索引:自定义的索引,叶子节点包含书签,通过书签离散地访问行数据;
联合索引:有2个字段的辅助索引
覆盖索引技术:从辅助索引中就可以取得记录
explain中key列表示是否使用索引,using where表示是否进行行数据后处理过滤
MRR优化:将键排序再顺序读取
ICP优化:取出索引即执行where过滤
B+树
1.从用途来说,有以下几种常见的索引:
B+树索引:查找到数据所在页
全文索引:
哈希索引:自动生成
2.B+树是为磁盘或其它直接存取辅助设备设计的一种平衡查找树
高度平衡:两个子树的高度差最大为1
高扇出性:一个结点的孩子结点数目,通常在100 以上或更多,使得高度一般2-4层
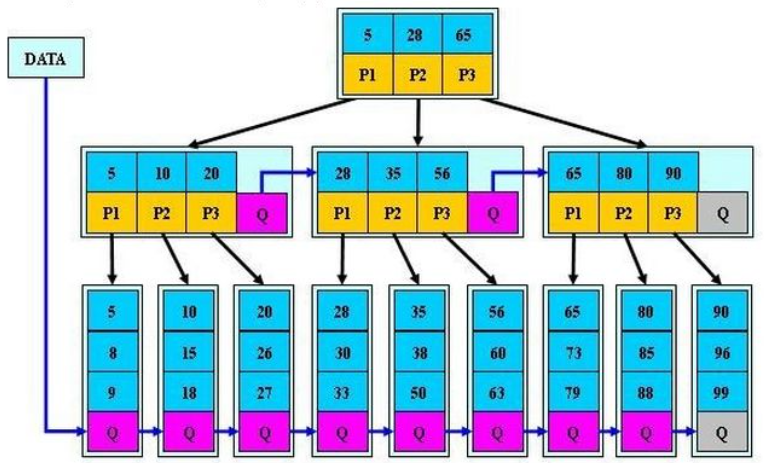
3.数据库中的B+树索引分为:
聚集索引 clustered index
辅助索引 secondary index
聚集索引
1.按照每张表的主键构造一颗B+树
2.每张表只能由一个聚集索引,数据排序的,特别适合范围值的查询 => 查询优化器优先选用
3.叶子节点存放行记录数据(数据页),非叶节点存放的是键值和指向数据页的偏移量
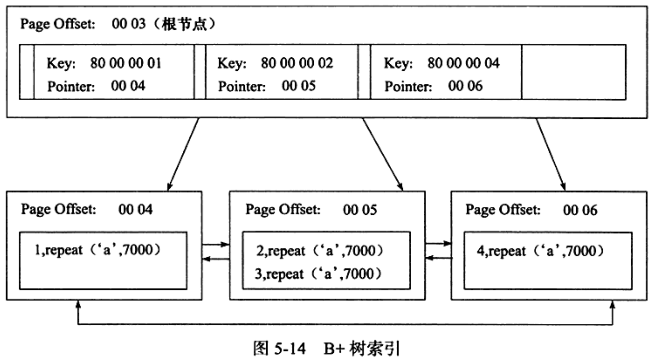
4.页通过双向链表链接,页按照主键的顺序排序(不一定是物理连续的),每个页中的数据也是按照双向链表维护的
5.聚集索引适合按主键的排序查找和范围查找
//排序查找
mysql> explain select * from actor order by actor_id limit 10;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+
| 1 | SIMPLE | actor | index | NULL | PRIMARY | 2 | NULL | 10 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+
//范围查找
mysql> explain select * from actor where actor_id > 0 and actor_id < 10;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | actor | range | PRIMARY | PRIMARY | 2 | NULL | 8 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
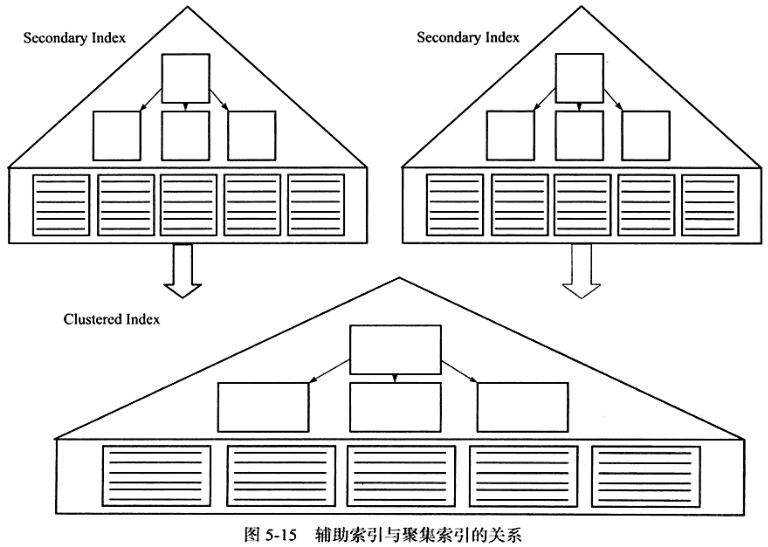
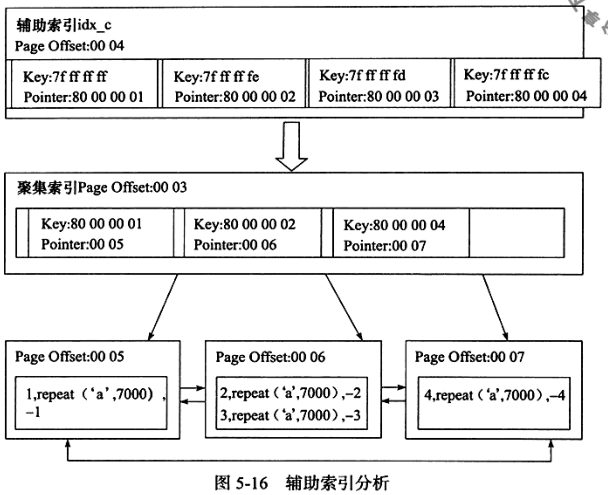
辅助索引
1.每张表上可以有多个辅助索引,叶子节点不包含行记录的全部数据,除了键值外,还包含一个书签bookmark
2.书签用于找到对应的行数据(一般是主键),用于后续在聚集索引中查找,或者是指向主键索引的地址pointer
3.堆表:行数据的存储按插入的顺序存放
B+树上的索引都是辅助索引,即非聚齐的 => 叶子节点不是行数据
叶子节点书签上存放行标志符Row Identifier,即文件号:页号:槽号
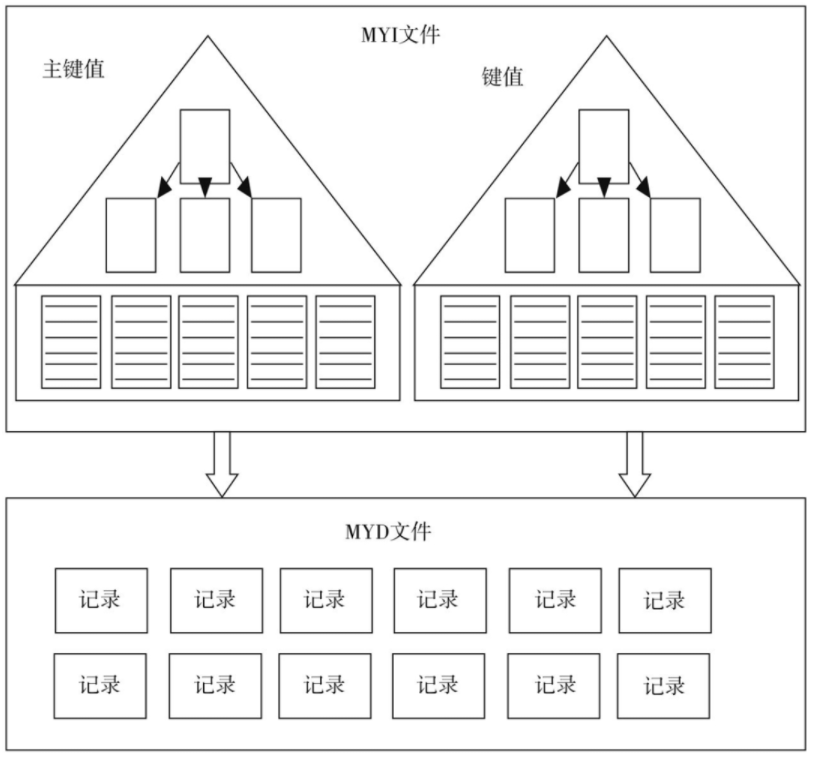
4.对比 堆表 和 索引组织表
堆表能实现更快的离散读,但在范围查找时没有优势,同时很难实现预读
所以MyISAM中在堆表的基础上还增加了索引组织表(辅助索引)
5.辅助索引数据放在独立的页中
索引的管理
1.2种创建和删除索引的方法
alter table <table> add index <index name> (<columns>);
alter table <table> drop index <index name>;
create index <index name> on <table> (<clolumns>);
drop index <index name> on <table>;
2.使用索引更有意义:取出表中少部分数据,且字段是高选择性的
=> 字段的可选值很多,有很多不重复的值,即cardinality/ROWS 接近1
3.cardinality的统计放在存储引擎层进行,基于采样完成,
索引的使用
1.OLTP应用特点:通过索引取得少部分数据;
OLAP应用特点:访问大量数据,索引的建立基于宏观用途,一般会对时间字段建立索引;
2.联合索引:左索引的查询将使用联合索引,右索引不适用
//假设有索引(a, b)
select * from <table> where a=xxx order by b;
select * from <table> where a=xxx and b=xxx;
select * from <table> where a=xxx and b=xxx order by c;
覆盖索引
1.覆盖索引 covering index:从辅助索引中就可以查询的记录,而不需要查询聚集索引中的记录;
辅助索引的节点中已经包含主键信息
2.常用于统计数量
优化器如何选择索引
1.当用户按范围选取,且取的是整行的数据时,无法使用覆盖索引
因为使用辅助索引后还需按书签访问整行的数据,变成了磁盘的离散度,所以优化器往往会选择聚集索引
select * from orderdetails where orderid > 1000 and orderid < 10000;
possible_keys中列出了所有可选的索引,但最终选择了聚合索引PRIMARY
同时Extra=Using Where表示使用了全表扫描(没有使用辅助索引)
mysql> explain select * from actor where actor_id>10 and actor_id<100;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | actor | range | PRIMARY | PRIMARY | 2 | NULL | 88 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
2.总结Extra中的含义
Using Index
表示直接访问索引就能够获取到所需要的数据(覆盖索引),不需要通过索引回表
Using Index Condition
新特性(Index Condition Pushdown);会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
Using where
表示MySQL服务器在存储引擎收到记录后进行“后过滤”(Post-filter),如果查询未能使用索引,Using where的作用只是提醒我们MySQL将用where子句来过滤结果集
Using filesort
MySQL中无法利用索引完成的排序操作称为“文件排序”
Using temporary
表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询
3.强制使用索引
select * from orderdetails FORCE INDEX(orderid) where orderid > 1000 and orderid < 10000;
强制索引也可i提高效率,减少优化器选择的成本
4.MRR优化 Multi-Range Read
用于减少磁盘的随机访问(通过对键排序,使得页访问变成顺序访问)
查询和配置MRR,默认打开
mysql> show variables like '%optimizer_switch%'\G;
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: mrr=on,mrr_cost_based=on
mrr_cost_based表示是否通过cost base方式决定是否启用mrr
5.ICP优化 Index Condition Pushdown
取出索引的同时,立即判断是否可以进行WHERE条件的过滤,可减少对行数据的访问
哈希表
1.碰撞解决技术:链表法
2.散列函数:除法散列,h(k) = k mod m
3.自适应哈希索引:只适用于等值查询
4.控制开关
mysql> show variables like '%innodb_adaptive_hash_index%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_adaptive_hash_index | ON |
+----------------------------+-------+
全文检索
1.前缀匹配搜索也可以利用索引进行快速查找
全文检索则需要进行索引的扫描
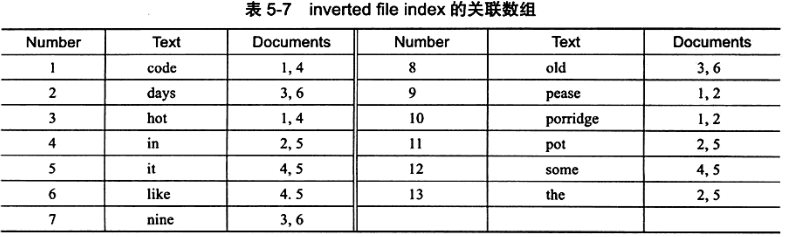
2.倒排索引 inverted index:在辅助表中存储了映射关系
inverted file index {单词, 单词所在文档id列表}
full inverted index {单词, (单词所在文档id, 在文档中的位置)}
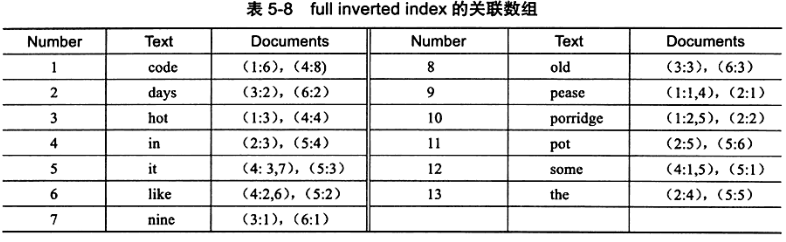
3.InnoDB采用 full inverted index
存储在表 Auxiliiary Table,共有6张,列是 word, list
设置参数指定分词对应信息
set global innodb_ft_aux_table='sakila/fts_a';
select * from information_schema.innodb_ft_index_table;
4.全文检索索引缓存 FTS Index Cache :提高性能
红黑树结构,类似InsertBuffer,但不是持久对象
修改文本->分词操作->插入FTS
查询文本->合并FTS到AuxiliaryTable->对Table查询
查看FTS缓存大小 innodb_ft_cache_size 默认8M
Variable_name: innodb_ft_cache_size
Value: 8000000
5.自动创建列 FTS_DOC_ID:为了在全文检索时,与word进行映射(引擎自动完成),类似Create Table时执行
FTS_DOC_ID BIGINT UNSIGNED AUTO_INCREMENT NOT NULL,
PRIMARY KEY(FTS_DOC_ID),
因为删除文本行时只是标记并添加到information_schema.innodb_ft_deleted表,所以索引会越来越大
使用optimize table来优化,以下配置单次删除的量
| innodb_ft_num_word_optimize | 2000 |